Kubernetes
Kubernetes is a cloud-native open-source system for deployment, scaling, and management of containerized applications.
It provides clustering and file system abstractions that allows the execution of containerised workloads across different cloud platforms and on-premises installations.
The built-in support for Kubernetes provided by Nextflow streamlines the execution of containerised workflows in Kubernetes clusters.
Concepts
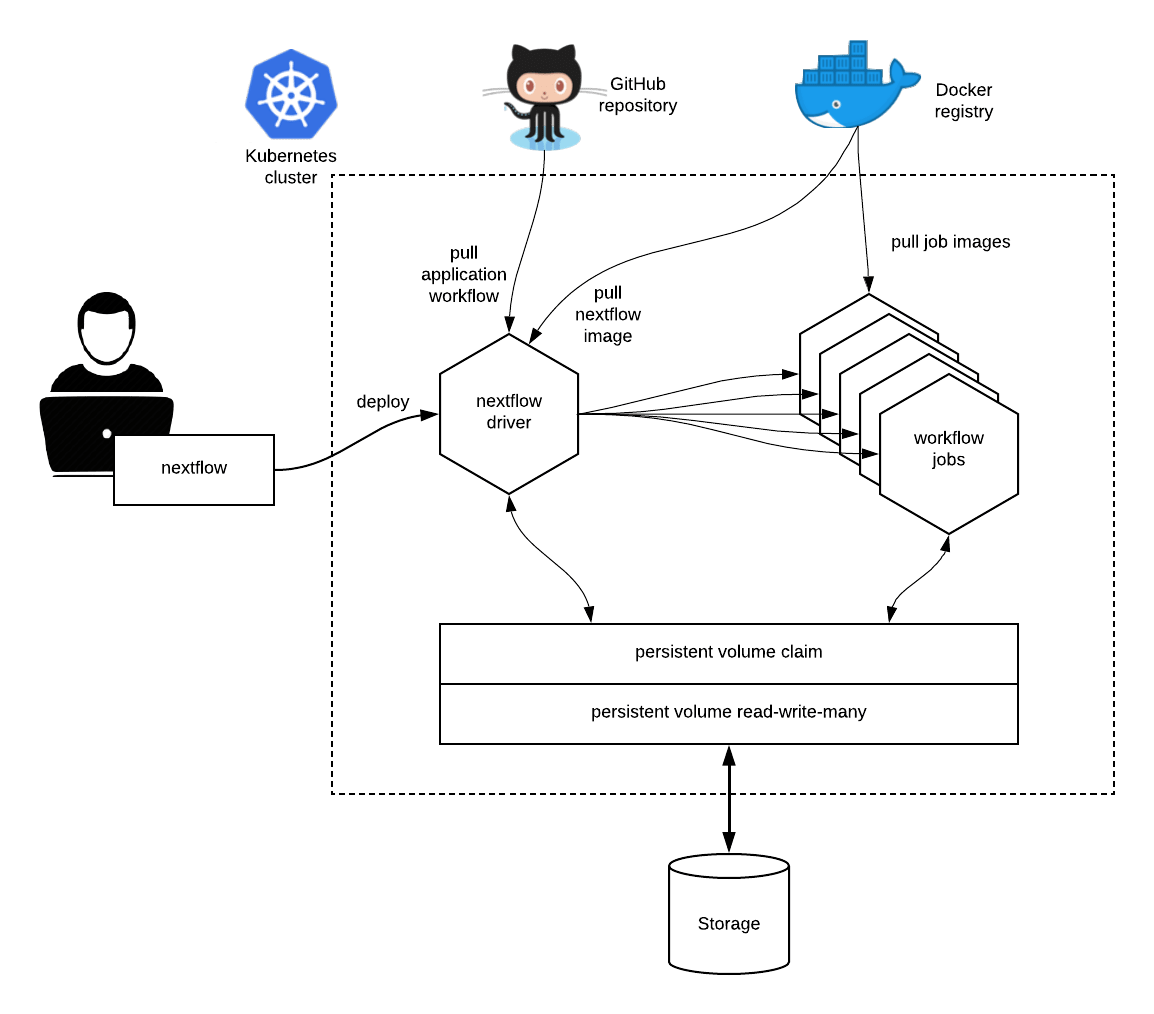
Kubernetes main abstraction is the pod. A pod defines the (desired) state of one or more containers i.e. required computing resources, storage, network configuration.
Kubernetes abstracts also the storage provisioning through the definition of one more persistent volumes that allow containers to access to the underlying storage systems in a transparent and portable manner.
When using the k8s executor Nextflow deploys the workflow execution as a Kubernetes pod. This pod orchestrates the workflow execution and submits a separate pod execution for each job that needs to be carried out by the workflow application.
Requirements
At least a Persistent Volume with ReadWriteMany access mode has to be defined in the Kubernetes cluster (check the supported storage systems at this link).
Such volume needs to be accessible through a Persistent Volume Claim, which will be used by Nextflow to run the application and store the scratch data and the pipeline final result.
The workflow application has to be containerised using the usual Nextflow container directive.
Tip
When using Wave containers and Fusion file system there is no need to use a shared file system and configure a persistent volume claim for the deployment of Nextflow pipeline with Kubernetes. You can ignore this requirement when using the Fusion file system. See the Fusion file system for further information.
Execution
The workflow execution needs to be submitted from a computer able to connect to the Kubernetes cluster.
Nextflow uses the Kubernetes configuration file available at the path $HOME/.kube/config or the file specified by the environment variable KUBECONFIG.
You can verify such configuration with the command below:
$ kubectl cluster-info
Kubernetes master is running at https://your-host:6443
KubeDNS is running at https://your-host:6443/api/v1/namespaces/kube-system/services/kube-dns:dns/proxy
Launch with kuberun
Warning
The kuberun is considered an obsolete approach for the deployment of Nextflow pipeline with Kubernetes and is no longer maintained. For a better alternative, consider using Launch with Fusion.
To deploy and launch the workflow execution use the Nextflow command kuberun as shown below:
nextflow kuberun <pipeline-name> -v vol-claim:/mount/path
This command will create and execute a pod running the nextflow orchestrator for the specified workflow. In the above example replace <pipeline-name> with an existing nextflow project or the absolute path of a workflow already deployed in the Kubernetes cluster.
The -v command line option is required to specify the volume claim name and mount path to use for the workflow execution. In the above example replace vol-claim with the name of an existing persistent volume claim and /mount/path with the path where the volume is required to be mount in the container. Volume claims can also be specified in the Nextflow configuration file, see the Kubernetes configuration section for details.
Once the pod execution starts, the application in the foreground prints the console output produced by the running workflow pod.
Interactive login
For debugging purpose it’s possible to execute a Nextflow pod and launch an interactive shell using the following command:
nextflow kuberun login -v vol-claim:/mount/path
This command creates a pod, sets up the volume claim(s), configures the Nextflow environment and finally launches a Bash login session.
Warning
The pod is automatically destroyed once the shell session terminates. Do not use it to launch long-running workflows in the background.
Launch with Fusion
New in version 22.10.0.
The use of Fusion file system allows deploying a Nextflow pipeline to a remote (or local) cluster without the need to use a shared file system and configure a persistent volume claim for the deployment of Nextflow pipeline with Kubernetes.
This also makes unnecessary the use of the special kuberun command for the pipeline execution.
See Amazon EKS for a guide to set up Fusion in Amazon EKS compute environments and Google Kubernetes Engine (GKE) for a guide to set up Fusion in GKE compute environments.
Running in a pod
Nextflow can be executed directly from a pod running in a Kubernetes cluster. In these cases you will need to use the plain Nextflow run command and specify the k8s executor and the required persistent volume claim in the nextflow.config file as shown below:
process {
executor = 'k8s'
}
k8s {
storageClaimName = 'vol-claim'
storageMountPath = '/mount/path'
storageSubPath = '/my-data'
}
In the above snippet replace vol-claim with the name of an existing persistent volume claim and replace /mount/path with the actual desired mount path (default: /workspace) and storageSubPath with the directory in the volume to be mounted (default: /).
Warning
The running pod must have been created with the same persistent volume claim name and mount as the one specified in your Nextflow configuration file. Note also that the run command does not support the -v option.
Tip
It is also possible to mount multiple volumes using the pod directive, for example:
k8s.pod = [ [volumeClaim: "other-pvc", mountPath: "/other" ]]
Pod settings
The process pod directive allows the definition of pods specific settings, such as environment variables, secrets and config maps when using the Kubernetes executor. See the pod directive for more details.
Limitations
The kuberun command does not allow the execution of local Nextflow scripts. It is only intended as a convenient way to test the deployment of pipelines to a Kubernetes cluster.
Advanced configuration
Read the Kubernetes configuration and executor sections to learn more about advanced configuration options.