
Containers have become an essential part of well-structured data analysis pipelines. They encapsulate applications and dependencies in portable, self-contained packages that can be easily distributed. Containers are also key to enabling predictable and reproducible results.
Nextflow was one of the first workflow technologies to fully embrace containers for data analysis pipelines. Community curated container collections such as BioContainers also helped speed container adoption.
However, the increasing complexity of data analysis pipelines and the need to deploy them across different clouds and platforms pose new challenges. Today, workflows may comprise dozens of distinct container images. Pipeline developers must manage and maintain these containers and ensure that their functionality precisely aligns with the requirements of every pipeline task.
Also, multi-cloud deployments and the increased use of private container registries further increase complexity for developers. Building and maintaining containers, pushing them to multiple registries, and dealing with platform-specific authentication schemes are tedious, time consuming, and a source of potential errors.
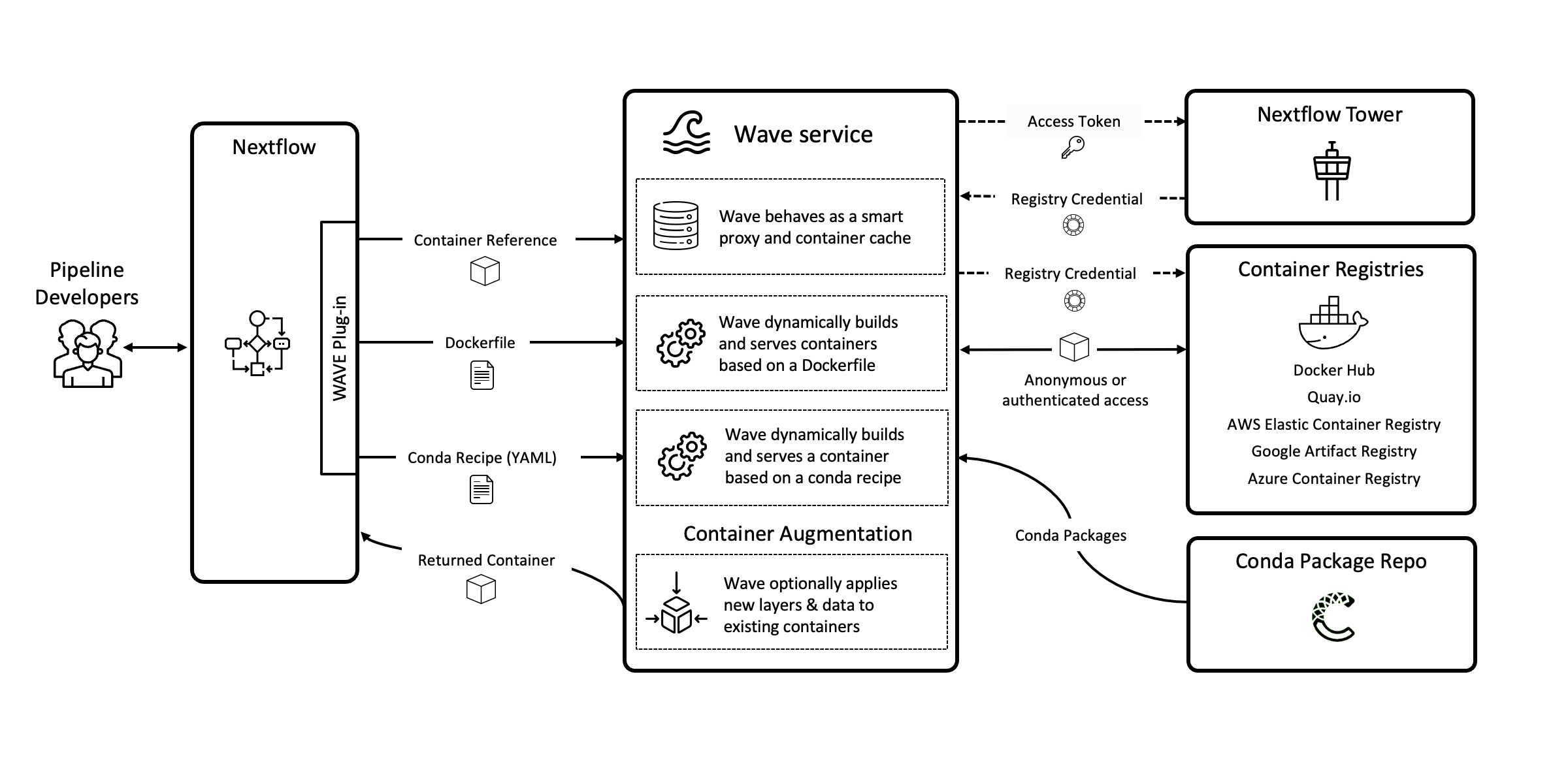
For these reasons, we decided to fundamentally rethink how containers are deployed and managed in Nextflow. Today we are thrilled to announce Wave — a container provisioning and augmentation service that is fully integrated with the Nextflow and Nextflow Tower ecosystems.
Instead of viewing containers as separate artifacts that need to be integrated into a pipeline, Wave allows developers to manage containers as part of the pipeline itself. This approach helps simplify development, improves reliability, and makes pipelines easier to maintain. It can even improve pipeline performance.
Instead of creating container images, pushing them to registries, and referencing them using Nextflow’s container directive, Wave allows developers to simply include a Dockerfile in the directory where a process is defined.
When a process runs, the new Wave plug-in for Nextflow takes the Dockerfile and submits it to the Wave service. Wave then builds a container on-the-fly, pushes it to a destination container registry, and returns the container used for the actual process execution. The Wave service also employs caching at multiple levels to ensure that containers are built only once or when there is a change in the corresponding Dockerfile.
The registry where images are stored can be specified in the Nextflow config file, along with the other pipeline settings. This means containers can be served from cloud registries closer to where pipelines execute, delivering better performance and reducing network traffic.
Conda is an excellent package manager, fully supported in Nextflow as an alternative to using containers to manage software dependencies in pipelines. However, until now, Conda could not be easily used in cloud-native computing platforms such as AWS Batch or Kubernetes.
Wave provides developers with a powerful new way to leverage Conda in Nextflow by using a conda directive as an alternative way to provision containers in their pipelines. When Wave encounters the conda directive in a process definition, and no container or Dockerfile is present, Wave automatically builds a container based on the Conda recipe using the strategy described above. Wave makes this process exceptionally fast (at least compared to vanilla Conda) by leveraging with the Micromamba project under the hood.
A long-standing problem with containers in Nextflow was the lack of support for private container registries. Wave solves this problem by acting as an authentication proxy between the Docker client requesting the container and a target container repository. Wave relies on Nextflow Tower to authenticate user requests to container registries.
To access private container registries from a Nextflow pipeline, developers can simply specify their Tower access token in the pipeline configuration file and store their repository credentials in Nextflow Tower page in your account. Wave will automatically and securely use these credentials to authenticate to the private container registry.
By automatically building and provisioning containers, Wave dramatically simplifies how containers are handled in Nextflow. However, there are cases where organizations are required to use validated containers for security or policy reasons rather than build their own images, but still they need to provide additional functionality, like for example, adding site-specific scripts or logging agents while keeping the base container layers intact.
Nextflow allows for the definition of pipeline level (and more recently module level) scripts executed in the context of the task execution environment. These scripts can be made accessible to the container environment by mounting a host volume. However, this approach only works when using a local or shared file system.
Wave solves these problems by dynamically adding one or more layers to an existing container image during the container image download phase from the registry. Developers can use container augmentation to inject an arbitrary payload into any container without re-building it. Wave then recomputes the image’s final manifest adding new layers and checksums on-the-fly, so that the final downloaded image reflects the added content.
With container augmentation, developers can include a directory called resources in pipeline module directories. When the corresponding containerized task is executed, Wave automatically mirrors the content of the resources directory in the root path of the container where it can be accessed by scripts running within the container.
One of the main motivations for implementing Wave is that we wanted to have the ability to easily package a Fusion client in containers to make this important functionality readily available in Nextflow pipelines.
Fusion implements a virtual distributed file system and presents a thin-client allowing data hosted in AWS S3 buckets to be accessed via the standard POSIX filesystem interface expected by the pipeline tools. This client runs in the task container and is added automatically via the Wave augmentation capability. This makes Fusion functionality available for pipeline execution at runtime.
This means the Nextflow pipeline can use an AWS S3 bucket as the work directory, and pipeline tasks can access the S3 bucket natively as a local file system path. This is an important innovation as it avoids the additional step of copying files in and out of object storage. Fusion takes advantage for the Nextflow tasks segregation and idempotent execution model to optimise and speedup file access operations.
Wave requires Nextflow version 22.10.0 or later and can be enabled by using the -with-wave command line option or by adding the following snippet in your nextflow.config file:
wave {
enabled = true
strategy = 'conda,container'
}
tower {
accessToken = "<your tower access token>"
}
The use of the Tower access token is not mandatory, however, it’s required to enable the access to private repositories. The use of authentication also allows higher service rate limits compared to anonymous users. You can run a Nextflow pipeline such as rnaseq-nf with Wave, as follows:
nextflow run nextflow-io/rnaseq-nf -with-wave
The configuration in the nextflow.config snippet above will enable the provisioning of Wave containers created starting from the conda requirements specified in the pipeline processes.
You can find additional information and examples in the Nextflow documentation and in the Wave showcase project.
The Wave container provisioning service is available free of charge as technology preview to all Nextflow and Tower users. Wave supports all major container registries including Docker Hub, Quay.io, AWS Elastic Container Registry, Google Artifact Registry and Azure Container Registry.
During the preview period, anonymous users can build up to 10 container images per day and pull 100 containers per hour. Tower authenticated users can build 100 container images per hour and pull 1000 containers per minute. After the preview period, we plan to make the Wave service available free of charge to academic users and open-source software (OSS) projects.
Software containers greatly simplify the deployment of complex data analysis pipelines. However, there still have been many challenges preventing organizations from fully unlocking the potential of this exciting technology. For too long, containers have been viewed as a replacement for package managers, but they serve a different purpose.
In our view, it’s time to re-consider containers as monolithic artifacts that are assembled separately from pipeline code. Instead, containers should be viewed simply as an execution substrate facilitating the deployment of the pipeline software dependencies defined via a proper package manager such as Conda.
Wave, Nextflow, and Nextflow Tower combine to fully automate the container lifecycle including management, provisioning and dependencies of complex data pipelines on-demand while removing unnecessary error-prone manual steps.